


Validated AI-Driven Target Identification and Biomarker Discovery with Insilico Medicine’s PandaOmics
Target identification is a critical part of early drug discovery. Just 10% of drugs in development make it from Phase I to approval, largely due to inadequate efficacy linked to poor target selection.
PandaOmics is a cloud-based software platform from clinical stage artificial intelligence (AI)-driven drug discovery company Insilico Medicine that helps researchers identify therapeutic targets and discover new biomarkers in order to select the most promising targets to pursue based on all available data and pre-existing research. A new paper in the Journal of Chemical Information and Modeling explores the features and provides definitive validation of this software platform.
“Target identification is a complex and critical part of the early drug discovery process,” says Insilico Medicine founder and co-CEO Alex Zhavoronkov, PhD. “So many drugs in development ultimately fail in clinical trials – a major drain on time and resources – due to poor efficacy. That, in turn, stems from choosing the wrong target.”
How PandaOmics Finds Promising Targets for Multiple Diseases
PandaOmics’ algorithm uses a massive database of pre-created datasets and meta-analyses, which is updated by Insilico's team of biologists and bioinformaticians. This system provides pathway activation analysis so users can better understand which biological processes, such as autophagy or DNA replication, are implicated in a disease. It also highlights connections between genes, biological pathways, and metadata in the context of a particular disease of interest. Through meta-analysis, users can then aggregate multiple disease-relevant genetic data.
To provide these insights, PandaOmics relies on diverse data from multiple sources – including scientific publications, grant applications, clinical trials, and omics data, which includes gene expression, genetics, proteomics, and methylation data.
More Targets, Expanded Indications
Within the Target ID interface alone, there are 23 disease-specific models. Using this interface, users can rank genes of interest based on specified criteria, which might include druggability by small molecules and therapeutic antibodies, safety considerations, novelty of the target, tissue-specific expression patterns, protein class, biological process involvement, availability of crystal structures, and the level of pharmaceutical development.
And users can also determine how a target might be relevant in multiple diseases. This is done via the Indication Prioritization feature, presented in a similar fashion as the Target ID interface. In it, diseases are grouped to align with the pipelines of leading pharma companies. These can be further categorized by therapeutic domains or specific tissue and organ systems. The Indication Prioritization feature relies on a repository of pre-calculated disease meta-analyses encompassing over 8,000 diseases, with a dedicated emphasis on more than 500 manually curated meta-analyses. PandaOmics also scores compounds and compares them to known targets or disease-associated genes, allowing for further prioritization.
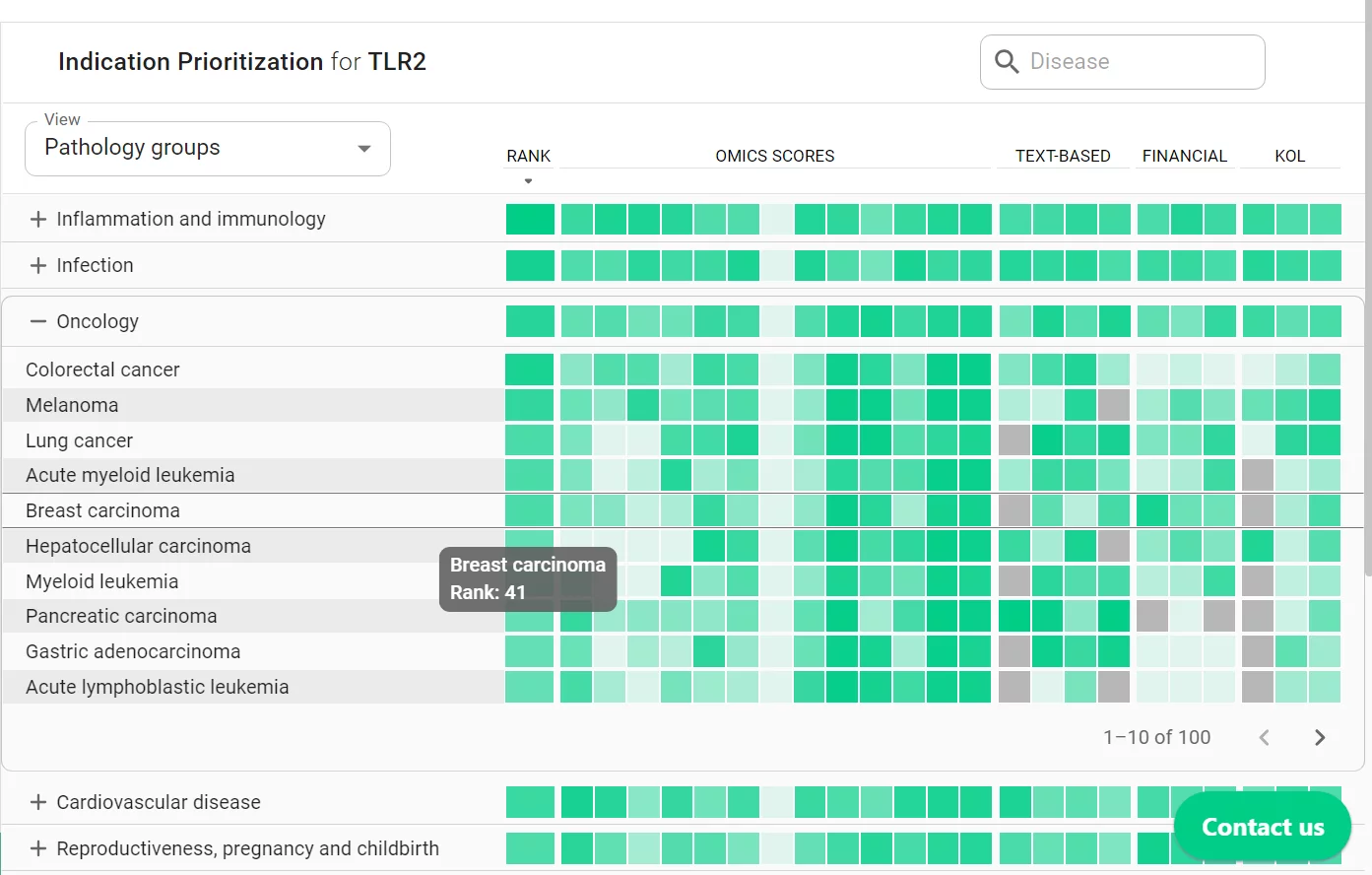
Interacting with the Data and Benefiting from Robotics
PandaOmics is designed to be accessible for anyone – and allows users to interact with the platform via a visually represented Knowledge Graph and chat functionality.
Using an advanced algorithm, the Knowledge Graph draws information from publications, clinical trials, and other data to provide a deeper understanding of the competitive landscape to underscore the value of a particular identified target. If users have questions, or want to dive deeper into the disease-target relationship, they can do so easily using the tool’s ChatPandaGPT functionality, a large language model feature that provides relevant summaries and answers questions.
PandaOmics further benefits from a steady supply of data coming from Insilico’s AI-powered next-generation robotics lab, Life Star. As the robotics lab performs target and compound validation, its sequencing and phenotypic data are fed back into the platform, enriching the dataset and enhancing the accuracy of its target and biomarker prediction. In turn, PandaOmics’ insights help guide the design and selection of targets for further validation and testing.

PandaOmics Proven Success Stories
Insilico recently released version 4.0 of PandaOmics, and the system has been extensively validated in biomarker discovery and target identification across multiple therapeutic areas, including oncology, inflammation, and immunology.
To date, the platform has identified potential biomarkers associated with androgenic alopecia, as well as with gallbladder cancer and smoke-induced lung cancer.
In terms of therapeutic targets, PandaOmics has successfully identified targets for idiopathic pulmonary and kidney fibrosis, aging, glioblastoma multiforme, and head and neck squamous cell carcinoma. Insilico’s lead AI-designed drug candidate for idiopathic pulmonary fibrosis, designed for a PandaOmics-identified target, is now in Phase II trials with patients, the first AI-designed drug for an AI-discovered target to reach this milestone.
In papers published in 2023, PandaOmics identified and successfully validated CAMMK2, MARCKS, and p62 in Alzheimer’s disease cell models and KDM1A as a dual aging and oncology target. In 2022, Insilico scientists worked with a consortium of researchers to identify 28 potential therapeutic targets for ALS using PandaOmics, which were later validated in animal models.
“It has been very exciting to see the advances in this platform in just a few years,” says Petrina Kamya, PhD, Head of AI Platforms and President of Insilico Medicine Canada. “PandaOmics is truly a state-of-the-art tool for early drug discovery and works seamlessly with other emerging technologies – including AlphaFold and new methods for detecting protein phase separation – to further advance its capabilities.”
Combining PandaOmics with AlphaFold and Other Breakthrough Technologies
PandaOmics has also been used in combination with other emerging technologies to further advance its capabilities. In 2023, Insilico published the successful application of Chemistry42, in combination with the AlphaFold protein structure prediction tool and PandaOmics, to identify a novel hit molecule for liver cancer against a novel target, CDK20, that lacked an experimental structure.
In 2023, Insilico published findings with a research team at the University of Cambridge on using PandaOmics with the FuzDrop method for predicting protein phase separation (PPS) to identify PPS-prone, disease-associated proteins.
“It has been challenging so far to understand the role of protein phase separation in cellular functions,” said Professor Michele Vendruscolo from Cambridge’s Yusuf Hamied Department of Chemistry, who led the research. “Even more difficult has been to clarify the exact nature of its association with human disease. By working with Insilico Medicine, we have developed an approach to systematically address this problem and identify a variety of possible therapeutic targets. We have thus provided a roadmap for researchers to navigate this complex terrain.”
PandaOmics is a key component of Insilico’s end-to-end Pharma.AI drug discovery platform which includes Chemistry42 for small molecule drug design and inClinico for virtual predictions of clinical trial outcomes. This software suite has been licensed by numerous pharma partners and given rise to Insilico’s robust internal pipeline of 31 drugs in development for numerous diseases including cancer, immunotherapy, fibrosis, IBD, and COVID-19, with 5 AI-designed therapeutic small molecules in clinical stages.